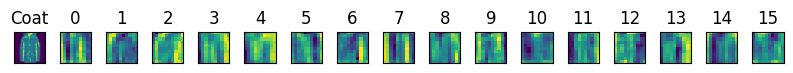Where I attempt to solve the exercises in section 7.6 of the d2l book from scratch in pytorch (without using the d2l library).
Imports
! pip3 install matplotlibimport torchimport torch.nn as nnimport torch.optim as optimfrom torchvision import datasets, transformsfrom torch.utils.data import DataLoader, Datasetfrom PIL import Imageimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport os, itertools, time= 'cuda'
Context
The book section ties together convolution/pooling layer concepts seen in previous sections and introduces the original LeNet architecture:
Which is succinctly defined in PyTorch as
nn.Sequential(
nn.LazyConv2d(6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.LazyConv2d(16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.LazyLinear(120), nn.Sigmoid(),
nn.LazyLinear(84), nn.Sigmoid(),
nn.LazyLinear(num_classes)
)Without forgetting to use uniform Xavier initialization. Let’s define the net:
class LeNet(nn.Module):def __init__ (self , num_classes):super ().__init__ ()self .net = nn.Sequential(6 , kernel_size= 5 , padding= 2 ), nn.Sigmoid(),= 2 , stride= 2 ),16 , kernel_size= 5 ), nn.Sigmoid(),= 2 , stride= 2 ),120 ), nn.Sigmoid(),84 ), nn.Sigmoid(),def forward(self , X):return self .net(X)# Used later on to initialize the weights def init_weights(m):if isinstance (m, nn.Linear) or type (m) == nn.Conv2d:
And try to train it without using the d2l library.
We first get our dataset and dataloaders. We’ll wrap it in a function for convinience later.
Get data and loaders
def get_data(dataset, batch_size):= {'root' : 'data' , 'transform' : transforms.ToTensor(), 'download' : True }= dataset(train = True , ** data_params)= dataset(train = False , ** data_params)= DataLoader(train_dataset, batch_size = batch_size, shuffle = True )= DataLoader(test_dataset, batch_size = batch_size, shuffle = False )return train_dataset, test_dataset, train_loader, test_loader= get_data(datasets.FashionMNIST, 128 )
And functions to evaluate our models and plot losses.
Model eval and loss ploting functions
def eval_model(model, test_loader): eval ()= 0 with torch.no_grad():for images, labels in test_loader:= images.to(device), labels.to(device)= torch.max (model(images), 1 )+= (pred == labels).float ().sum ().item()return correct / len (test_loader.dataset)def plot_results(losses, test_acc):'Epoch' ); plt.ylabel('Cross Entropy Loss' )f'Test Accuracy: { test_acc:.2f} ' )
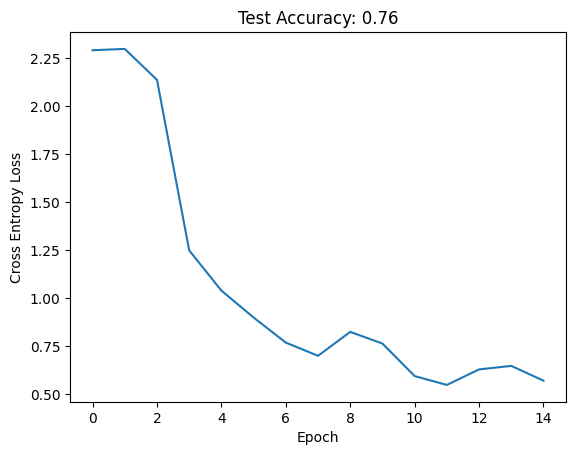
And finally train it using SGD with learning rate 0.1 for 15 epochs
Code
def train(net, train_loader, lr = 0.1 , epochs = 15 , verbose = True ):# Infer input shapes, initialize weights and move to device = net(next (iter (train_loader))[0 ]) # Necessary before initing weights apply (init_weights)= nn.CrossEntropyLoss()= optim.SGD(net.parameters(), lr = lr)= []for epoch in range (epochs):for images, labels in train_loader:= images.to(device), labels.to(device)= criterion(net(images), labels)if verbose: print (f'Epoch: { epoch + 1 } \t Loss: { loss. item():.2f} ' )return losses= LeNet(10 )= train(net, train_loader, verbose = False )= eval_model(net, test_loader)
And we achieve reasonable performance. Let’s now attempt the section questions.
Q1
Let’s modernize LeNet. Implement and test the following changes:
Replace average pooling with max-pooling.
Replace the softmax layer with ReLU.
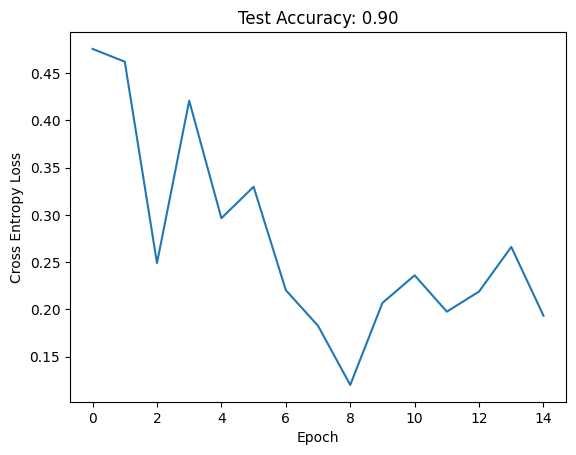
We define another module and replace nn.Sigmoid’s for nn.ReLu’s and nn.AvgPool2d’s for nn.MaxPool2d’s:
class ModernLeNet(nn.Module):def __init__ (self , num_classes):super ().__init__ ()self .net = nn.Sequential(6 , kernel_size= 5 , padding= 2 ), nn.ReLU(),= 2 , stride= 2 ),16 , kernel_size= 5 ), nn.ReLU(),= 2 , stride= 2 ),120 ), nn.ReLU(),84 ), nn.ReLU(),def forward(self , X):return self .net(X)
Code
= ModernLeNet(10 )= train(net, train_loader, verbose = False )= eval_model(net, test_loader)
And we achieve a non-trivial improvement in performance. We even observed the loss increase slightly, indicating that our learning rate it too high (or we should decrease it on a schedule).
Q2
Try to change the size of the LeNet style network to improve its accuracy in addition to max-pooling and ReLU.
Adjust the convolution window size.
Lets make everything a parameter:
class TweakableModernLeNet(nn.Module):def __init__ (self , num_classes, conv_kernel = 5 , out_channels = [6 , 16 ],= [120 , 84 ]):super ().__init__ ()= [= conv_kernel, padding= 2 ), nn.ReLU(),= 2 , stride= 2 )) for out_c in out_channels+ [nn.Flatten()] + [for dim in hidden_dims+ [nn.LazyLinear(num_classes)]self .net = nn.Sequential(* layers)def forward(self , X):return self .net(X)
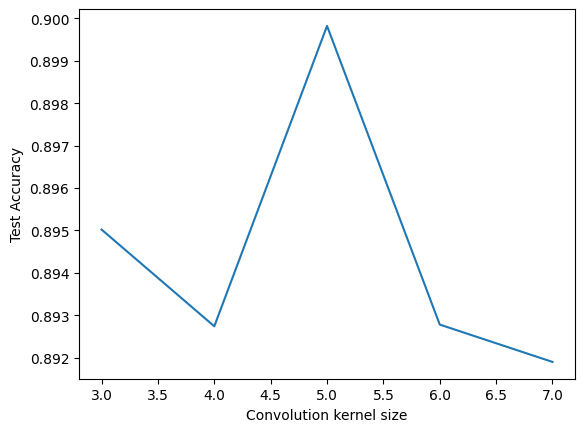
Let’s try adjusting the convolution window size \(c_w \in \{3,..,7\}\) . We’ll train 5 nets per size and report the average:
Changing convolution window size
= 5 = range (3 , 7 + 1 )= []for conv_size in conv_sizes:= 0 for _ in range (n_avg):= TweakableModernLeNet(10 , conv_kernel = conv_size)= False )+= eval_model(net, test_loader)/ n_avg)'Convolution kernel size' ); plt.ylabel('Test Accuracy' )
Text(0, 0.5, 'Test Accuracy')
Looking at the y-axis, it seems the kernel size has only a small effect on performance in this case, and that 5 is a reasonable choice.
Adjust the number of output channels.
We can try halving, doubling and tripling the original [6, 16] output channels:
Changing output channel sizes
= 3 = [[3 , 8 ], [6 , 16 ], [12 , 22 ], [24 , 44 ]]= []for out_c in out_channels:= 0 for _ in range (n_avg):= TweakableModernLeNet(10 , out_channels = out_c)= False )+= eval_model(net, test_loader)'Output channels' : out_c, 'Test Accuracy' : avg / n_avg})= pd.DataFrame(df)
0
[3, 8]
0.885500
1
[6, 16]
0.894867
2
[12, 22]
0.901233
3
[24, 44]
0.908233
Again, the gains seem marginal and increase compute so the original seems reasonable.
Adjust the number of convolution layers.
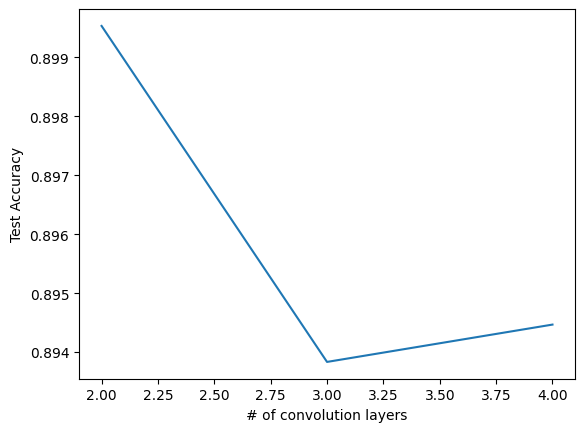
Lets try adding up to 2 additional convolution layers:
Adding convolution layers
= 3 = [[6 , 16 ], [6 , 16 , 22 ], [6 , 16 , 22 , 28 ]]= []for out_c in out_channels:= 0 for _ in range (n_avg):= TweakableModernLeNet(10 , out_channels = out_c)= False )+= eval_model(net, test_loader)/ n_avg)len (i) for i in out_channels], test_accs)'# of convolution layers' ); plt.ylabel('Test Accuracy' )
Text(0, 0.5, 'Test Accuracy')
Same as above (see y-axis).
Adjust the number of fully connected layers.
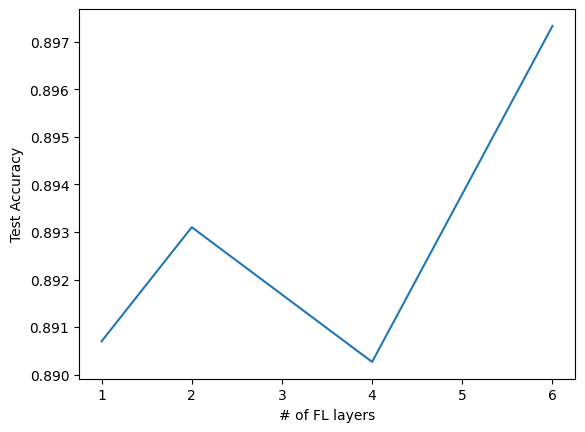
Lets try 1, the original 2, 4, and 6 layers:
Adding number of FL layers
= 3 = [[84 ], [120 , 84 ], [120 , 120 , 84 , 84 ], [120 , 120 , 120 , 84 , 84 , 84 ]]= []for hid_dims in hidden_dims:= 0 for _ in range (n_avg):= TweakableModernLeNet(10 , hidden_dims = hid_dims)= False )+= eval_model(net, test_loader)/ n_avg)len (i) for i in hidden_dims], test_accs)'# of FL layers' ); plt.ylabel('Test Accuracy' )
Text(0, 0.5, 'Test Accuracy')
Same.
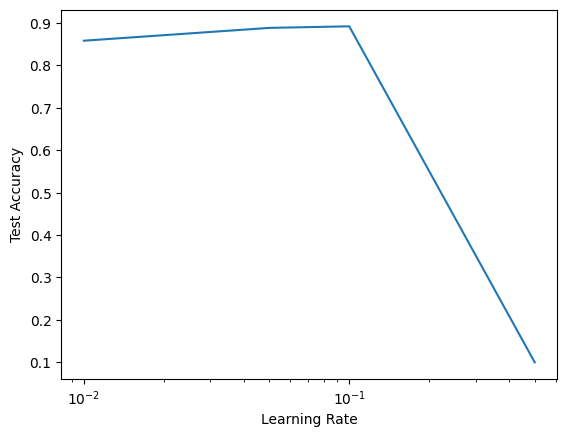
Adjust the learning rates and other training details (e.g., initialization and number of epochs).
Lets first experiment with different learning rates and try \(\{0.01, 0.05, 0.1, 0.5\}\) :
Different learning rates
= [0.01 , 0.05 , 0.1 , 0.5 ]= []for lr in lrs:= TweakableModernLeNet(10 )= False , lr = lr)'Learning Rate' ); plt.ylabel('Test Accuracy' )'log' )
It seams only 0.5 is too high and that our original 0.1 performs well.
Q3
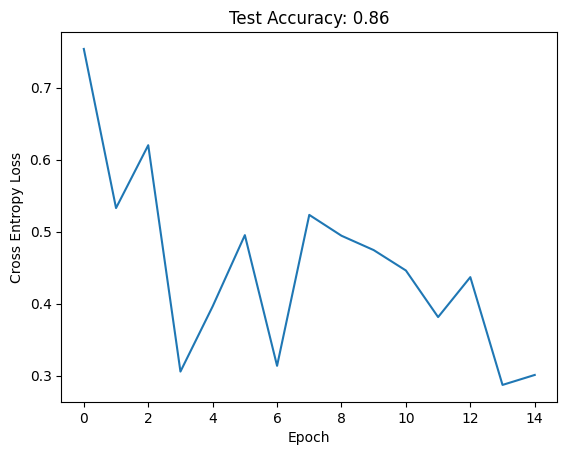
Try out the improved network on the original MNIST dataset
We can reuse code from above:
ModernLeNet of MNIST
= get_data(datasets.MNIST, 128 )= ModernLeNet(10 )= train(net, train_loader, verbose = False , lr = 0.01 )= eval_model(net, test_loader)
Epoch: 1 Loss: 0.75
Epoch: 2 Loss: 0.53
Epoch: 3 Loss: 0.62
Epoch: 4 Loss: 0.31
Epoch: 5 Loss: 0.40
Epoch: 6 Loss: 0.50
Epoch: 7 Loss: 0.31
Epoch: 8 Loss: 0.52
Epoch: 9 Loss: 0.49
Epoch: 10 Loss: 0.47
Epoch: 11 Loss: 0.45
Epoch: 12 Loss: 0.38
Epoch: 13 Loss: 0.44
Epoch: 14 Loss: 0.29
Epoch: 15 Loss: 0.30
And we get good performance.
Q4
Display the activations of the first and second layer of LeNet for different inputs (e.g., sweaters and coats)
Lets retrain the ModernLeNet on FashionMNIST:
Retrain ModernLeNet on MNIST
= ModernLeNet(10 )= train(net, train_loader, verbose = False )= eval_model(net, test_loader) print ('Test acc: ' , test_acc)
And now get a few sweater and coat images:
Get images of coats and sweaters
= get_data(datasets.FashionMNIST, 128 )= next (iter (train_loader))= train_dataset.classes.index('Coat' )= train_dataset.classes.index('Pullover' )= [ix for ix, y in enumerate (ys) if y == coat_ix][:n]= [ix for ix, y in enumerate (ys) if y == sweater_ix][:n]
Remmember that the ReLUs are at indeces 1 and 4:
Code
ModernLeNet(
(net): Sequential(
(0): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU()
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(4): ReLU()
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Flatten(start_dim=1, end_dim=-1)
(7): Linear(in_features=400, out_features=120, bias=True)
(8): ReLU()
(9): Linear(in_features=120, out_features=84, bias=True)
(10): ReLU()
(11): Linear(in_features=84, out_features=10, bias=True)
)
)
We can subscript into Sequential to obtain the activations and each channel along with the input:
Function to display activations
# Prepare img: add minibatch dim and move to device def disp_acts(end_layer, images = None ):if images is None : images = [imgs[coats_ix[0 ]], imgs[sweaters_ix[0 ]]]for name, og_img in zip (['Coat' , 'Sweater' ], images):= og_img[None , :].to(device) = net.net[:end_layer](img)= activation.shape[1 ]= plt.subplots(1 , n_channels + 1 , figsize = (8 ,5 ))0 ].imshow(og_img.permute(1 , 2 , 0 ))0 ].set_xticks([]); axs[0 ].set_yticks([]); axs[0 ].set_title(name)for ax, channel in zip (axs[1 :], range (n_channels)):1 , 2 , 0 )[:, :, channel].detach().to('cpu' ).numpy())str (channel))1 )
And we observe that the first activation layer seems to detect lines, edges, etc. - low-level features, while the second activation layer is slightly more abstract features (although they are hard to interpret).
Q5
What happens to the activations when you feed significantly different images into the network (e.g., cats, cars, or even random noise)?
Lets try inputing random noise:
Code
1 , [torch.randn((1 , 28 , 28 )), torch.randn((1 , 28 , 28 ))])
Code
4 , [torch.randn((1 , 28 , 28 )), torch.randn((1 , 28 , 28 ))])
And the activations seem completely random, as we would expect.