Where I build up intuition for RNNs and attempt to solve the exercises in section 9.5 of the d2l book from scratch in pytorch (without using the d2l library).
First, a little context and intermediate implementations that helped me understand the one the book and Pytorch follow. For better explainers see [1],[2],[3].
Context
RNNs are layers that maintain a state \(\mathbf{H}_t\) and update it every time you a forward pass. The new value at “time” \(t\) depends on the current input \(\mathbf{X}_t\) and the previous value \(\mathbf{H}_{t-1}\) according to
What about the dimensions? There are two choices we get to make. The first is the dimension \(d\) of the vectors we represent our words/characters/tokens with that will dictate the shape of our input \(\mathbf{X}_t \in \mathbb{R}^{n \times d}\), where \(n\) is the batch size. The second is the hidden dimension \(h\) we wish to transform our tokens to, which will dictate the shape of the hidden state as \(\mathbf{H}_t \in \mathbb{R}^{n \times h}\).
We can visualize the layer by displaying how it behaves across forward passes \(t-1\), \(t\), \(t+1\) by “unrolling time” horizontally.
Fig. 9.4.1 From the book.
We first sort out the data we will feed the RNN, mainly following sections 9.2 and 9.3 implemented from scratch.
Get and preprocess data
# url = 'http://d2l-data.s3-accelerate.amazonaws.com/' + 'timemachine.txt'# with open('data/timemachine.txt', 'w') as f:# f.write(requests.get(url).text)withopen('data/timemachine.txt', 'r') as f: text = f.read()text = re.sub('[^A-Za-z]+', ' ', text).lower() # ignore punctuation: 'the time machine by h g wells i the time traveller ...'tokens =list(text) # character-level tokens: ['t', 'h', 'e', ' ', 't', 'i', 'm', 'e', ...]vocab =set(tokens) # unique characters: {' ', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', ...}char_to_ix = {c:i for i, c inenumerate(vocab)} # character to index: {' ': 0, 'a': 1, 'b': 2, 'c': 3, ...}ix_to_char = {i:c for i, c inenumerate(vocab)} # index to character: {0: ' ', 1: 'a', 2: 'b', 3: 'c', ...}# Just so we can use torch's DataLoadersclass OffsetSequences(Dataset):def__init__(self, tokens, seq_len): self.tokens = tokens;self.seq_len = seq_lendef__len__(self): returnlen(self.tokens) -self.seq_lendef__getitem__(self, idx):if idx >=len(self): raiseIndexError t =lambda l: torch.Tensor(l).long()return t(self.tokens[idx:idx +self.seq_len]), t(self.tokens[idx +1:idx +1+self.seq_len])# Hyperparamsdef get_data(batch_size, num_steps, train_prop =0.7): train_cutoff =int(train_prop *len(tokens)) train_dataset = OffsetSequences([char_to_ix[t] for t in tokens[:train_cutoff]], num_steps) test_dataset = OffsetSequences([char_to_ix[t] for t in tokens[train_cutoff:]], num_steps) train_loader = DataLoader(train_dataset, batch_size = batch_size, shuffle =True, drop_last =True) test_loader = DataLoader(test_dataset, batch_size = batch_size, shuffle =False, drop_last =True)return train_dataset, test_dataset, train_loader, test_loaderbatch_size, num_steps =1024, 16train_dataset, test_dataset, train_loader, test_loader = get_data(batch_size, num_steps)train_dataset_demo, test_dataset_demo, train_loader_demo, test_loader_demo = get_data(2, 3)
We can now obtain sequences of our text data offset by one to feed as input and targets. Let’s display the first few tokenized characters of the text and the first (input, target) pair when we set the sequence length num_steps to 3:
X, Y = train_dataset_demo[0][char_to_ix[i] for i in tokens[:5]], X, Y
In practice, we’ll have much larger sequence lengths, and batch sizes and will set shuffle=True to grab random sequences from the corpus. Finally, we need to one-hot encode the tokens (Sec. 9.5.2.1) and end up with the shape (sequence length, batch size, vocab size):
X = F.one_hot(X.T, len(vocab)).type(torch.float32)X.shape # seq_length, batch_size, vocab_size
torch.Size([3, 2, 27])
Since we are now ready to start feeding in data let’s start with a literal implementation of the above description of the RNN layer:
A literal implementation
class RNNScratch(nn.Module):"""The RNN model implemented from scratch."""def__init__(self, num_inputs, num_hiddens, num_outputs, sigma =0.01):super().__init__()self.num_inputs = num_inputs;self.num_hiddens = num_hiddens;self.num_outputs = num_outputsself.W_xh = nn.Parameter(torch.randn(num_inputs, num_hiddens) * sigma)self.W_hh = nn.Parameter(torch.randn(num_hiddens, num_hiddens) * sigma)self.b_h = nn.Parameter(torch.zeros(num_hiddens))self.W_hq = nn.Parameter(torch.randn(num_hiddens, num_outputs) * sigma)self.b_q = nn.Parameter(torch.zeros(num_outputs))def forward(self, X, H =None):# X: (batch_size, vocab_size)if H isNone: H = torch.zeros(X.shape[0], self.num_hiddens) H = torch.tanh(torch.matmul(X, self.W_xh) + torch.matmul(H, self.W_hh) +self.b_h) O = torch.matmul(H, self.W_hq) +self.b_qreturn O, H
Remember we feed RNNs tokens sequentially. Let’s first feed in the first tokens and inspect the output shapes.
Which makes sense since the layer must output, for each example in the batch, (the logits for) which of the 27 characters is more likely to follow the input. We also have the layer output the updated hidden state H to pass in the next forward pass(es):
Since we’ve now reached the end of the sequence we can compare the predicted and actual last word to compute a loss:
F.cross_entropy(output, Y.T[-1])
tensor(3.2961, grad_fn=<NllLossBackward0>)
With this simple setup, we can already train a simple language model:
Train small lm
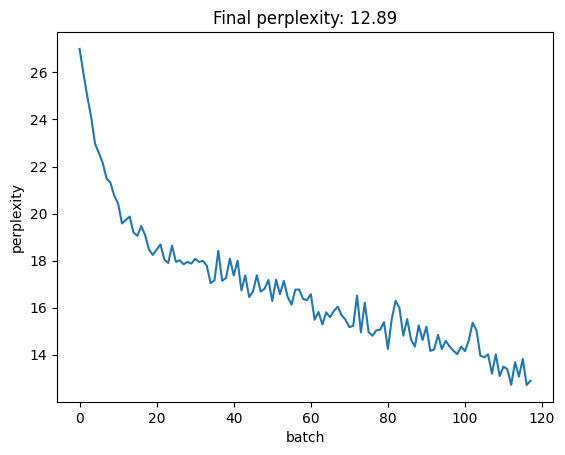
# train on train_loader, not train_loader_demom = RNNScratch(num_inputs =len(vocab), num_hiddens =32, num_outputs =len(vocab))opt = optim.SGD(m.parameters(), lr =1)losses = []for X, Y in train_loader: X = F.one_hot(X.T, len(vocab)).type(torch.float32) opt.zero_grad() hidden_state =Nonefor i inrange(num_steps): output, hidden_state = m(X[i], hidden_state) loss = F.cross_entropy(output, Y.T[-1]) loss.backward() opt.step() losses.append(np.exp(loss.item()))plt.plot(losses); plt.ylabel('perplexity'); plt.xlabel('batch'); plt.title(f'Final perplexity: {losses[-1]:.2f}')
Text(0.5, 1.0, 'Final perplexity: 12.89')
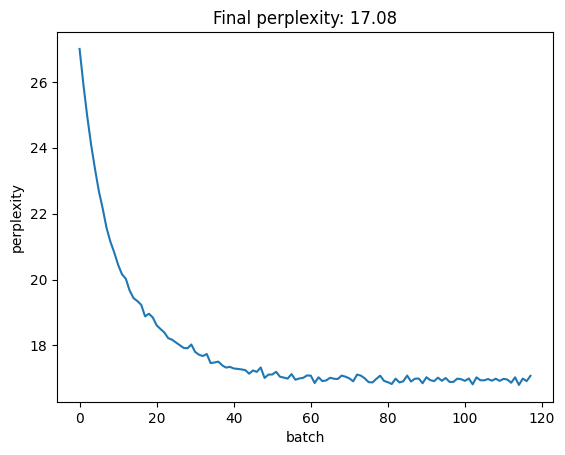
Now instead of only teaching the network to predict the last character of the sequence using all the previous ones \((x_t | x_{t-1}, ~\dots~x_1)\) we could “increase de signal” in our loss by evaluating all intermediate predictions \((x_2 | x_1)\), \((x_3|x_2, x_1)\), …, \((x_t | x_{t-1}, ~\dots~x_1)\). We can do so by accumulating the intermediate logits in a list, stacking them, and then making sure our shapes make sense before passing to cross_entropy. Here we assume all intermediate predictions are equally weighted in the loss, but you could play around with this.
Why do we get a higher loss? Well, asking the RNN to make correct intermediate predictions is a harder task than just predicting the last character. Thus we probably require more training, capacity, and tuning.
Anyway, our training loop is getting pretty messy. To match the book’s implementation and tidy up our loop we can first let the RNN loop though the sequence itself:
Code
class RNNScratch(nn.Module):"""The RNN model implemented from scratch."""def__init__(self, num_inputs, num_hiddens, num_outputs, sigma =0.01):super().__init__()self.num_inputs = num_inputs;self.num_hiddens = num_hiddens;self.num_outputs = num_outputsself.W_xh = nn.Parameter(torch.randn(num_inputs, num_hiddens) * sigma)self.W_hh = nn.Parameter(torch.randn(num_hiddens, num_hiddens) * sigma)self.b_h = nn.Parameter(torch.zeros(num_hiddens))self.W_hq = nn.Parameter(torch.randn(num_hiddens, num_outputs) * sigma)self.b_q = nn.Parameter(torch.zeros(num_outputs))def forward(self, X, H =None):# Expects X: (seq_length, batch_size, num_inputs i.e. vocab_size)# Outputs X: (seq_len, batch_size, num_outputs i.e. vocab_size)if H isNone: H = torch.zeros(X.shape[1], self.num_hiddens) # (batch_size, num_hiddens) outputs = []for X_i in X: # loop over first dim H = torch.tanh(torch.matmul(X_i, self.W_xh) + torch.matmul(H, self.W_hh) +self.b_h) O = torch.matmul(H, self.W_hq) +self.b_q outputs.append(O)return torch.stack(outputs), H
And make sure the output shapes still make sense:
Code
m = RNNScratch(num_inputs =len(vocab), num_hiddens =32, num_outputs =len(vocab))X, Y =next(iter(train_loader_demo))X = F.one_hot(X.T, len(vocab)).type(torch.float32)outputs, H = m(X)outputs.shape, H.shape
(torch.Size([3, 2, 27]), torch.Size([2, 32]))
Finally, the book and Pytorch don’t include the output linear layer in the RNN layer. This way we can have the RNN layer focus only on updating the hidden state and could use it to generate output using a linear layer or something more complicated like a whole decoder module.
RNN layer without output layer
class RNNScratch(nn.Module):"""The RNN model implemented from scratch."""def__init__(self, num_inputs, num_hiddens, sigma =0.01):super().__init__()self.num_inputs = num_inputs;self.num_hiddens = num_hiddensself.W_xh = nn.Parameter(torch.randn(num_inputs, num_hiddens) * sigma)self.W_hh = nn.Parameter(torch.randn(num_hiddens, num_hiddens) * sigma)self.b_h = nn.Parameter(torch.zeros(num_hiddens))def forward(self, X, H =None):# Expects X: (seq_length, batch_size, num_inputs i.e. vocab_size)# Outputs: (seq_len, batch_size, num_outputs i.e. vocab_size)if H isNone: H = torch.zeros(X.shape[1], self.num_hiddens) hidden_states = [] # we now return all hidden statesfor X_i in X: H = torch.tanh(torch.matmul(X_i, self.W_xh) + torch.matmul(H, self.W_hh) +self.b_h) hidden_states.append(H)return torch.stack(hidden_states)
We can now define a language model module to deal with generating the output, embedding the input, and sampling sequences from the model.
RNN Language Model
class RNNLM(nn.Module):def__init__(self, vocab_size, num_hiddens, sigma =0.01):super().__init__()self.vocab_size = vocab_sizeself.rnn = RNNScratch(vocab_size, num_hiddens, sigma)self.W_hq = nn.Parameter(torch.randn(num_hiddens, vocab_size) * sigma)self.b_q = nn.Parameter(torch.zeros(vocab_size))def embed(self, X): return F.one_hot(X.T, self.vocab_size).type(torch.float32)def output_layer(self, hidden_states):return torch.stack([torch.matmul(H, self.W_hq) +self.b_q for H in hidden_states])def forward(self, X, H =None): hidden_states =self.rnn(self.embed(X), H)returnself.output_layer(hidden_states)@torch.no_grad()def generate(self, preamble, num_chars, char_to_ix): generation = preamble prepare_X =lambda char: self.embed(torch.Tensor([[char_to_ix[char]]]).long()) hidden_state =Nonefor char in preamble: # warm-up hidden_state =self.rnn(prepare_X(char), hidden_state)[-1] # only the last hidden statefor _ inrange(num_chars): # generation hidden_state =self.rnn(prepare_X(generation[-1]), hidden_state)[-1] output =self.output_layer([hidden_state]) generation += ix_to_char[output.argmax(dim =2).item()]return generation
Let’s test it out. We first sample a sequence continuation before training the model.
m = RNNLM(vocab_size =len(vocab), num_hiddens =32)m.generate('it has', 20, char_to_ix)
'it hasxhkzwytyqdmuvngggggg'
And train the model, now with the simplified training loop. To imitate Section 9.5.4. of the book, we do not use intermediate predictions and clip the gradients to magnitude 1 using nn.utils.clip_grad_norm_.
Evaluation function
@torch.no_grad()defeval(m, test_loader): m.eval() loss =0for X, Y in test_loader: outputs = m(X) outputs = outputs[-1] targets = Y[:, -1] loss += F.cross_entropy(outputs, targets).item()return np.exp(loss /len(test_loader)) # perplexity
Train the model
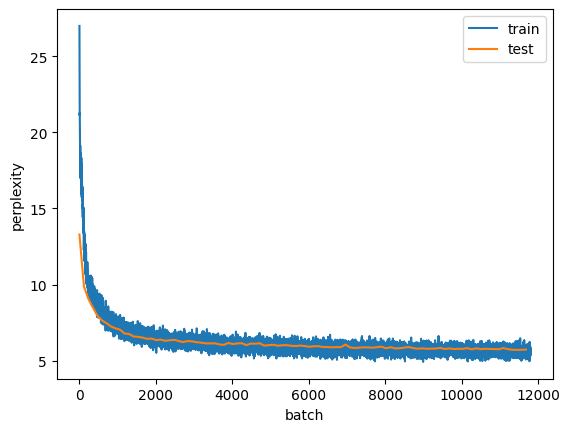
opt = optim.SGD(m.parameters(), lr =1)train_perplexities, test_perplexities = [], []for _ inrange(100):for X, Y in train_loader: opt.zero_grad() outputs = m(X) outputs = outputs[-1] targets = Y[:, -1] loss = F.cross_entropy(outputs, targets) loss.backward() nn.utils.clip_grad_norm_(m.parameters(), 1) # Clip the gradient opt.step() train_perplexities.append(np.exp(loss.item())) test_perplexities.append(eval(m, test_loader))plt.plot(train_perplexities, label ='train')plt.plot(list(range(0, len(train_perplexities), len(train_loader))),test_perplexities, label ='test')plt.legend(); plt.xlabel('batch'); plt.ylabel('perplexity')
Text(0, 0.5, 'perplexity')
Finally, let’s see what the trained model generates:
m.generate('it has', 20, char_to_ix)
'it hase the stound the sto'
I think that is enough context. Let’s get to some of the exercises I found interesting.
1
Does the implemented language model predict the next token based on all the past tokens up to the very first token in The Time Machine?
In general no. The model is trained to predict the next token based only on the previous num_steps tokens. However, after generation, you could pass in the whole of The Time Machine to the model in the warm-up phase and then ask it to predict the next token. In principle the prediction would be based on all tokens up to the very first token but since the model has to compress every token it has seen into the hidden state it’s likely to not remember much of the beginning of the text.
2
Which hyperparameter controls the length of history used for prediction?
num_steps during training and the length of prefix during inference.
3
Show that one-hot encoding is equivalent to picking a different embedding for each object.
One-hot embedding assigns each object a vector of zeros that is of size # of objects with a 1 in the unique entry that corresponds to the object. Thus every object has a distinct embedding.
5
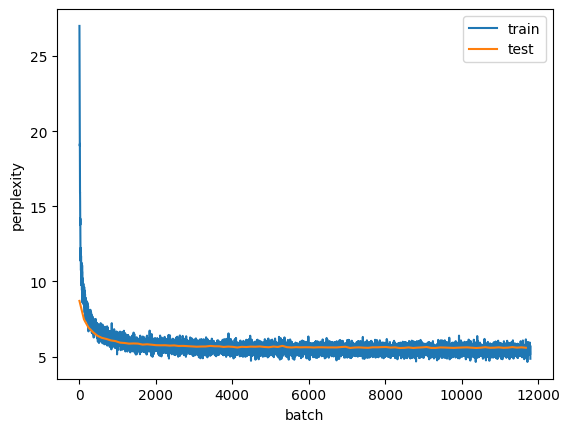
Replace one-hot encoding with learnable embeddings. Does this lead to better performance?
We can simply add an embedding module to the language model:
opt = optim.SGD(m.parameters(), lr =1)train_perplexities, test_perplexities = [], []for _ inrange(100):for X, Y in train_loader: opt.zero_grad() outputs = m(X) outputs = outputs[-1] targets = Y[:, -1] loss = F.cross_entropy(outputs, targets) loss.backward() nn.utils.clip_grad_norm_(m.parameters(), 1) # Clip the gradient opt.step() train_perplexities.append(np.exp(loss.item())) test_perplexities.append(eval(m, test_loader))plt.plot(train_perplexities, label ='train')plt.plot(list(range(0, len(train_perplexities), len(train_loader))),test_perplexities, label ='test')plt.legend(); plt.xlabel('batch'); plt.ylabel('perplexity')
Text(0, 0.5, 'perplexity')
I.e. we got comparable results using one-hot encoding and learnable embeddings did not seem to improve performance.
6
Conduct an experiment to determine how well this language model trained on The Time Machine works on other books by H. G. Wells, e.g., The War of the Worlds.
Evaluate on other texts
def eval_on_other_text(m, url): text = requests.get(url).text text = re.sub('[^A-Za-z]+', ' ', text).lower() tokens =list(text) test_dataset = OffsetSequences([char_to_ix[t] for t in tokens[:10000]], num_steps) test_loader = DataLoader(test_dataset, batch_size = batch_size, shuffle =False, drop_last =True)returneval(m, test_loader)perplexities = {'time machine': eval(m, test_loader),'the sleeper awakes': eval_on_other_text(m, 'https://gutenberg.org/cache/epub/12163/pg12163.txt'),'the war of the worlds': eval_on_other_text(m, 'https://gutenberg.org/cache/epub/36/pg36.txt'),'britling sees it through': eval_on_other_text(m, 'https://gutenberg.org/cache/epub/14060/pg14060.txt'),'certain personal matters': eval_on_other_text(m, 'https://gutenberg.org/cache/epub/17508/pg17508.txt'),}perplexities
{'time machine': 5.590489799933571,
'the sleeper awakes': 7.463832230616033,
'the war of the worlds': 6.850138662194433,
'britling sees it through': 8.232215427642316,
'certain personal matters': 7.385997756118561}
We get increased losses on texts by the same author, presumably (and hopefully) because of changes in the stories, plot lines, etc. What about texts from other authors?
7
Conduct another experiment to evaluate the perplexity of this model on books written by other authors.
With the first 3 texts I tried at first, there wasn’t that much of a jump in perplexities. Evaluating the model in the last text in Spanish served as a sanity check.
8
Modify the prediction method so as to use sampling rather than picking the most likely next character.
What happens?
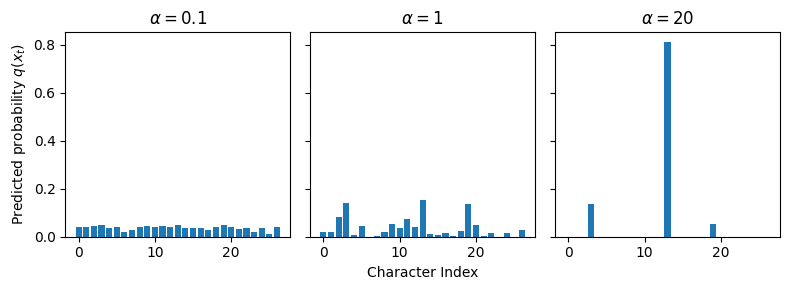
Bias the model towards more likely outputs, e.g., by sampling from \(q(x_t | x_{t-1}, ~\dots~, x_1) \propto P(x_t | x_{t-1}, ~\dots~, x_1)^\alpha\) for $> 1 $
We can do so by multiplying the logits by \(\alpha\) (inverse temperature) before applying softmax. Notice that as \(\alpha \rightarrow 0\) we sample tokens uniformly at random, and as \(\alpha \rightarrow +\infty\) we’ll select the most probable token.
alpha: 0.1 generation:friday furzziis ushxthfr
alpha: 1 generation:friday thought filltise to
alpha: 2 generation:friday to little the prese
alpha: 10 generation:friday the shate in the si
9
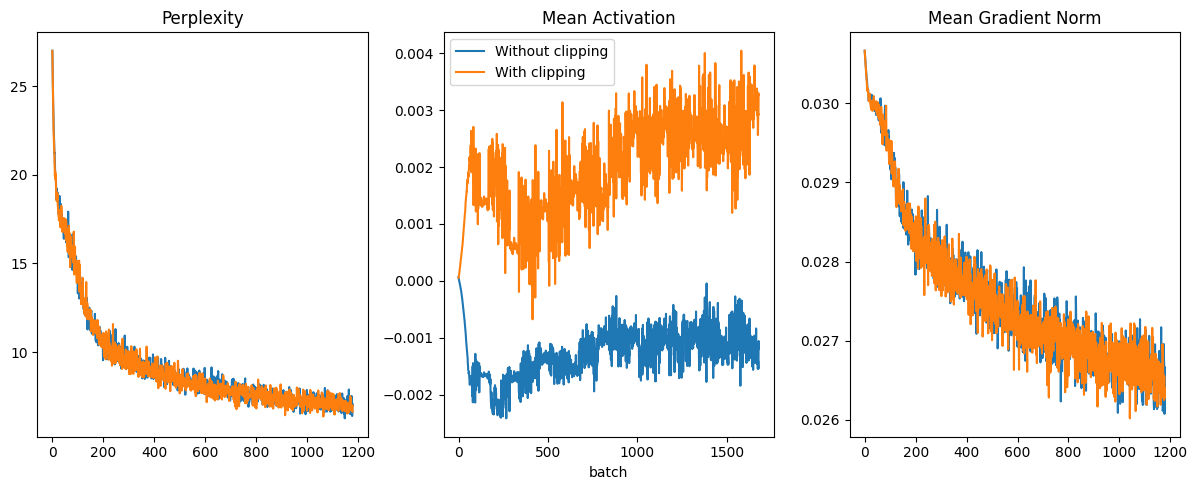
Run the code in this section without clipping the gradient. What happens?
I was expecting exploding gradients and, thus, for the network to be untrainable, but surprisingly I did not observe it. I tried increasing the sequence length from 32 to 256, adding hooks to debug, etc. Nothing.