The paper shows that neural networks can keep generalizing when large numbers of (non-adversarially) incorrectly labeled examples are added to datasets (MNIST, CIFAR, and ImageNet). It also appears that larger networks are more robust and that higher noise levels lead to lower optimal (fixed) learning rates.
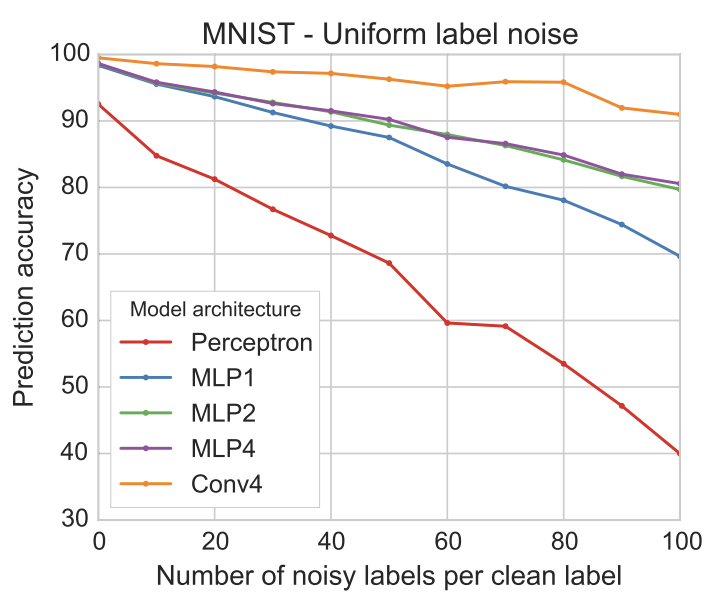
We’ll focus on the uniform label noise experiment and attempt to reproduce Figure 1:
Figure 1. As we increase the amount of noise in the dataset the performance drops. However, note that even when there are 100 noisy labels per clean label performance is still acceptable. For example, the Convnet still achieves 91% accuracy.
Note: As far as I can tell the paper has no accompanying code so I’ll be filling in the details to the best of my abilities.
Imports and model evaluation function
import torchimport torch.nn as nnimport torch.optim as optimfrom torchvision import datasets, transformsfrom torch.utils.data import DataLoader, Datasetfrom PIL import Imageimport numpy as npimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltimport os, itertools, timeos.makedirs('logs', exist_ok =True)os.makedirs('models', exist_ok =True)seed =42np.random.seed(seed)torch.manual_seed(seed)device = torch.device('cuda'if torch.cuda.is_available() else ('mps'if torch.backends.mps.is_available() else'cpu'))device ='cpu'# faster for the small models we are usingdef eval_model(model, test, criterion = nn.CrossEntropyLoss()): model.eval() correct, loss =0, 0.0with torch.no_grad():for images, labels in test: images, labels = images.to(device), labels.to(device) _, pred = torch.max(model(images), 1) correct += (pred == labels).float().sum().item() loss += criterion(model(images), labels).item()return loss /len(test.dataset), correct /len(test.dataset)
To generate the uniform label noise the paper augments the original dataset with an additional \(\alpha\)\((X_i, Y')\) pairs, where \(Y'\) is a class sampled uniformly at random with replacement.
To minimize disk use I opted for a custom dataset that wraps the original. Pytorch only requires we override __len__ and __getitem__. The length is simply the original size plus the amount of noisy labels. When queried for data we’ll generate the noisy labels for the original pairs immediately after it. For example when \(\alpha = 2\):
Note that to guarantee that noisy labels are consistent between epocs, i.e. data[1] returns the same class when called again, we can’t sample the labels at query time. To avoid storing all the randomly sampled labels (\(60, 000 \times 100\) in the worst case), we simply return a shifted index’s label. We can do this with MNIST because its reasonably class-balanced and shuffled.
class NoisyLabelDataset(Dataset):"""Adds alpha noisy labels per original example"""def__init__(self, dataset, alpha):self.dataset = datasetself.alpha = alphaself.shift = np.random.randint(0, len(dataset))def__len__(self): n =len(self.dataset)return n + (self.alpha * n)def__getitem__(self, idx): x, y =self.dataset[idx // (self.alpha +1)]if idx % (self.alpha +1) !=0: y =self.dataset[(idx +self.shift) %len(self.dataset)][1]return x, y
Although the paper appears to only include a test set, we also include a validation set to perform early stopping with.
Our training loop is pretty standard. We use the Adadelta optimizer as per the paper. Although the paper does not mention it, we assume they used early stopping: stop training when the validation accuracy does not increase after patience epochs and return the model with the highest validation accuracy.
Training function
def train(model, train_loader, val_loader, lr =0.01, patience =3, max_epochs =100, verbose =False): model.to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adadelta(model.parameters(), lr = lr) log = {'train_loss': [], 'val_loss': [], 'val_acc': []} best_val_acc =float('inf') best_model =Nonefor epoch inrange(max_epochs): model.train()for images, labels in train_loader: images, labels = images.to(device), labels.to(device) optimizer.zero_grad() loss = criterion(model(images), labels) loss.backward() optimizer.step() val_loss, val_acc = eval_model(model, val_loader) log['train_loss'].append(loss.item()) log['val_loss'].append(val_loss) log['val_acc'].append(val_acc)if verbose: print(', '.join([f'Epoch {epoch +1}'] + [f'{k}: {v[-1]:.4f}'for k, v in log.items()]))if val_acc < best_val_acc: best_val_acc = val_acc best_model = model.state_dict()# Early stopping: stop if val acc has not increased in the last `patience` epochsif epoch > patience and val_acc <=max(log['val_acc'][-patience-1:-1]): breakif best_model: model.load_state_dict(best_model)return model, log
We train with learning rates \(\{0.01, 0.05, 0.1, 0.5\}\) as per the paper and \(\alpha \in \{0, 25, 50\}\) to save some compute (we should get the idea). Below we define our perceptron, MLPs with 1, 2, and 4 layers and a 4-layer Convnet. Again, since the paper does not specify hidden dims, activations, or the convnet architecture, we set it ourselves.
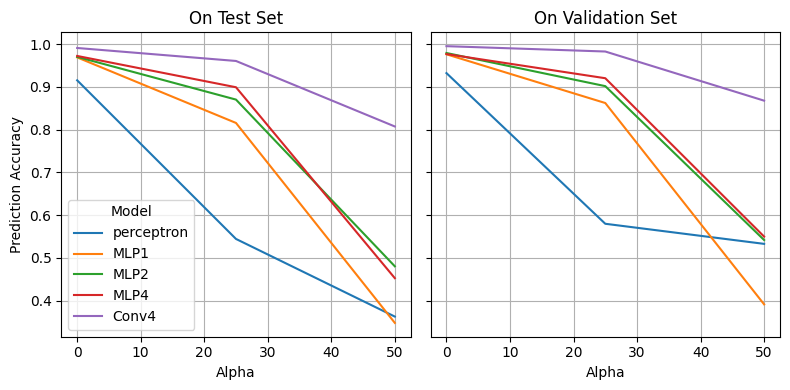
Finally, we plot the accuracies on both the validation and test sets:
Plot results
# Load results into dataframedf = []for fname in os.listdir('logs'): name, alpha, lr = fname.split('_') lr =float(lr.replace('.pt', '')) alpha =int(alpha) log = torch.load('logs/'+ fname) tmp = {} tmp['Model'] = name tmp['Alpha'] = alpha tmp['lr'] = lr tmp['Prediction Accuracy'] = log['test_acc'] tmp['Validation Accuracy'] =max(log['val_acc']) df.append(tmp)df = pd.DataFrame(df)hue_order = ['perceptron', 'MLP1', 'MLP2', 'MLP4', 'Conv4']f, (ax1, ax2) = plt.subplots(1, 2, figsize = (8, 4), sharey =True, sharex =True)sns.lineplot( df.groupby(['Model', 'Alpha']).max(), x ='Alpha', y ='Prediction Accuracy', hue ='Model', hue_order = hue_order, ax = ax1)ax1.set_title('On Test Set')ax1.grid()sns.lineplot( df.groupby(['Model', 'Alpha']).max(), x ='Alpha', y ='Validation Accuracy', hue ='Model', hue_order = hue_order, ax = ax2, legend =False)ax2.set_title('On Validation Set')ax2.grid()plt.tight_layout()
We observe that the general trends seem to hold. As we add noise the performance drops and larger models tend to be more robust.
However, our models overall tend to perform worse than the paper’s. At \(\alpha = 50\) most of our models have accuracies below \(60\%\), whereas the paper’s are around the high \(80\%\)’s. In addition, our Conv4 model is already below 90% when the paper archives 91% at \(\alpha = 100\).
This might be due to differences in training (use and implementation of early stopping), architecture implementation, random seeds (we did not try multiple / averaging because of compute), etc.
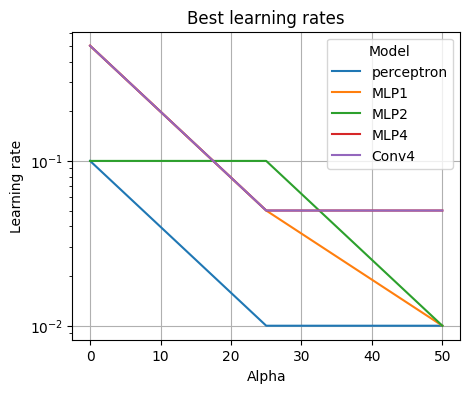
We also observe the trend the paper points out (in Section 5) that higher noise levels lead to smaller effective batch sizes and thus lower optimal learning rates:
A few closing thoughts: Although our results did not completely align with the paper, we still find the robustness to noise impressive.
The paper performs and studies the effect much further under non-uniform noise, with different datasets, batch sizes, etc. It is worth a read.
I might revisit this notebook to perform further experiments and try to answer some lingering questions:
Does within epoch sample ordering matter? Intuitively, if we place all clean labels before the noisy ones, one expects worse performance (catastrophic forgetting?)
What effect does early stopping have? We used a clean validation set to determine when to stop – which is not realistic. What happens if we use the loss or no early stopping?