This paper argues that memorization is a behavior exhibited by networks trained on random data, as, in the absence of patterns, they can only rely on remembering examples. The authors investigate this phenomenon and make three key claims:
Networks do not exclusively memorize data.
Networks initially learn simple patterns before resorting to memorization.
Regularization prevents memorization and promotes generalization.
Here we aim to reproduce Figures 1, 7, and 8 from the paper.
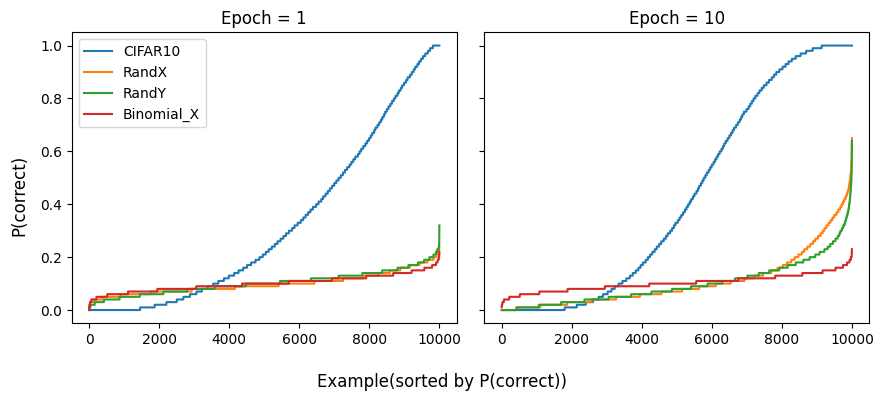
Fig 1
To support the first claim, the authors argue if networks simply memorize inputs they perform equally when on different training examples. However, if networks learn patterns, there should be points that are easy to learn because they fit these patterns better than others. To see if this is the case they train an MLP for a single epoch starting from 100 different initializations and data shufflings and log the percentage of times an example was correctly classified.
The experiment is performed with the CIFAR10 dataset, a noisy input version RandX, and a noisy label version RandY. We first define dataset wrappers to implement the noisy variants. Note that for epoch-to-epoch consistency we determine which examples to corrupt at initialization.
Random dataset wrappers
class RandX(Dataset):"""Injects example noise into dataset by replacing x% of inputs with random gaussian N(0, 1) noise"""def__init__(self, dataset, x =1.0):self.dataset = datasetself.x = xself.modified = {}for idx, (img, _) inenumerate(self.dataset):if np.random.rand() <= x:self.modified[idx] = torch.randn_like(img) torch.save(self.modified, os.path.join(dataset.root, 'randX_modified'))def__len__(self): returnlen(self.dataset)def__getitem__(self, idx): X, y =self.dataset[idx]returnself.modified.get(idx, X), y class RandY(Dataset):"""Injects example noise into dataset by replacing y% of labels with random labels"""def__init__(self, dataset, y =1.0):self.dataset = datasetself.y = yself.modified = {}for idx inrange(len(self.dataset)):if np.random.rand() <= y:self.modified[idx] = np.random.randint(0, len(self.dataset.classes)) torch.save(self.modified, os.path.join(dataset.root, 'randY_modified'))def__len__(self): returnlen(self.dataset)def__getitem__(self, idx): X, y =self.dataset[idx]return X, self.modified.get(idx, y)
Now we define a standard training loop, initialization functions, and the MLP specified in the paper.
And run the experiment, training models for a single epoch as in the paper but also after 10 epochs to investigate how results vary.
Get estimated P(correct)
def add_missclassified(missclassified, model, test_set, batch_size =256): model = model.to(device); model.eval() test = DataLoader(test_set, batch_size = batch_size, shuffle =False) i =0with torch.no_grad():for images, labels in test: images, labels = images.to(device), labels.to(device) _, pred = torch.max(model(images), 1) missclassified[i:i + test.batch_size] += (pred != labels).float() i += test.batch_sizedef gen_fig_1(epochs =1, n_inits =100): training_sets = [train_set, RandX(train_set, x =1.0), RandY(train_set, y =1.0)]for training_set in training_sets: missclassified = torch.zeros(len(test_set)).to(device)for _ inrange(n_inits): m = MLP() initialize_model(m, DataLoader(train_set, batch_size =256)) train(m, training_set, test_set, optim.SGD(m.parameters(), lr =0.01), epochs = epochs) add_missclassified(missclassified, m, test_set) missclassified /= n_inits torch.save(missclassified, f'logs/missclassified_epochs={epochs}_'+ training_set.__class__.__name__)gen_fig_1(epochs =1, n_inits =100)gen_fig_1(epochs =10, n_inits =100)
Plot results
f, (ax1, ax2) = plt.subplots(1, 2, figsize = (9, 4), sharey =True)for ax, epochs inzip([ax1, ax2], [1, 10]):for fname insorted([f for f in os.listdir('logs') if'missclassified'in f andf'epochs={epochs}_'in f]): missclassified = torch.load(os.path.join('logs', fname)) p = (1- missclassified).sort().values.to('cpu').numpy() ax.plot(p, label = fname.split('_')[-1])# Plot binomially sampled points randX_mean =1- torch.load(os.path.join('logs', 'missclassified_RandX')).mean().item() bin_data = np.random.binomial(n =100, p = randX_mean, size =10000) /100 bin_data.sort() ax.plot(bin_data, label ='Binomial_X') ax.set_title(f'Epoch = {epochs}')ax1.legend()f.supylabel('P(correct)')f.supxlabel('Example(sorted by P(correct))')f.tight_layout()
Observe that the left is a figure very similar to the paper’s. Whereas real data has easy patterns that can be learned in a single epoch, random data does not and networks must resort to memorization. After 10 epochs we observe that the networks trained on random data manage to improve the performance on a few points at the expense of the rest, whose performance becomes worse than random.
Out of curiosity here are the 10 easiest and hardest examples.
Plot hardest and easiest examples
n =10f, ax = plt.subplots(2, n, figsize = (n -2, 2))for i, idx inenumerate(torch.sort(p).indices[:n]): img, label = test_set[idx] ax[0][i].imshow(img.permute(1, 2, 0).numpy()) ax[0][i].axis('off') ax[0][i].set_title(test_set.classes[label].replace('mobile', ''))for i, idx inenumerate(torch.sort(p).indices[-n:]): img, label = test_set[idx] ax[1][i].imshow(img.permute(1, 2, 0).numpy()) ax[1][i].axis('off') ax[1][i].set_title(test_set.classes[label].replace('mobile', ''))f.suptitle('Hardest (top) and easiest (bottom) examples')f.tight_layout()
Fig 2
The fact that networks learn patterns when trained on real data and don’t when trained on noise can also be visualized by plotting the first layer weights of a convolutional network. We show the weights for networks trained for 10 epochs on real and random data.
And we are able to see that the filters learned by the network trained on real data are much more structured and seem useful in contrast to the ones learned by training on noise.
Fig 9
To attempt to show that networks trained on real data are simpler hypotheses because they learn patterns, the authors introduce Critical Sample Ratio as a way to measure complexity. The idea is to
“estimate the complexity by measuring how densely points on the data manifold are present around the model’s decision boundaries. Intuitively, if we were to randomly sample points from the data distribution, a smaller fraction of points in the proximity of a decision boundary suggests that the learned hypothesis is simpler.”
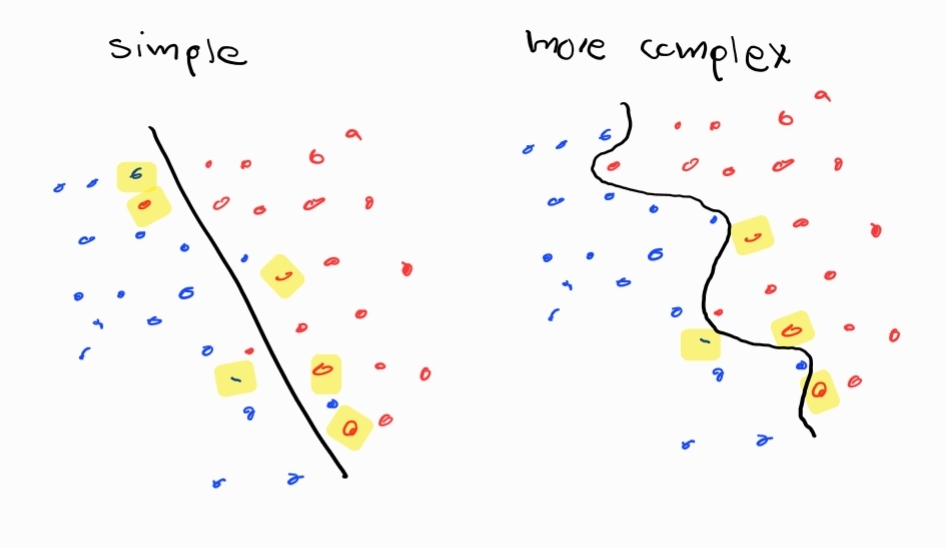
A simple sketch illustrates:
CSR intuition sketch
To estimate the density of points close to decision boundaries we might perturb the original data points within a box of size \(r\) and see if we cross the boundary. If a point crosses a boundary we call it “critical”. The Critical Sample Ratio is then the proportion of points that are critical and we expect simpler networks to have lower CSRs.
The perturbation done to data points is not totally random. The technique used by the paper is presented in Algorithm 1, borrows ideas from adversarial attacks, and is called Langevin Adversarial Sample Search (LASS). Here is how I implemented it.
LASS implementation
def standard_normal(shape): r = torch.randn(shape) r = r.to(device)return rdef lass(model, x, alpha =0.25/255, beta =0.2/255, r =0.3/255, eta = standard_normal, max_iter =10):""" Langevin Adversarial Sample Search (LASS). Finds a perturbation of x that changes the model's prediction. labels: Tensor of true labels corresponding to the input x. alpha: Step size for the gradient sign method. beta: Scaling factor for the noise. r: Clipping radius for adversarial perturbations. eta: Noise process. """# Orignal predictionwith torch.no_grad(): pred_on_x = model(x).argmax(dim=1) x_adv = x.clone().detach().requires_grad_(True) converged =False iter_count =0whilenot converged and iter_count < max_iter: iter_count +=1# Forward pass to get model output x_adv.requires_grad_(True) output = model(x_adv)# Compute gradient of the output with respect to input loss = F.cross_entropy(output, pred_on_x) # Use actual labels loss.backward()# Compute the perturbation gradient_sign = x_adv.grad.sign() delta = alpha * gradient_sign + beta * eta(x_adv.shape)with torch.no_grad(): x_adv += delta# Apply the clipping to each dimension so that each pixel is in the range [x - r, x + r] x_adv = torch.clamp(x_adv, x - r, x + r)# Check if the adversarial example has changed the model's prediction new_output = model(x_adv)ifnot torch.equal(output.argmax(dim=1), new_output.argmax(dim=1)): converged =True x_hat = x_adv.clone().detach()# Zero the gradients for the next iteration model.zero_grad()if x_adv.grad isnotNone: x_adv.grad.zero_()return converged, x_hat if converged elseNonedef compute_csr(model, test_set, n_examples =None, shuffle =False, **lass_kwargs):if n_examples isNone: n_examples =len(test_set) model = model.to(device) csr =0for i, (images, labels) inenumerate(DataLoader(test_set, batch_size =1, shuffle = shuffle)):if i == n_examples: break images, labels = images.to(device), labels.to(device) converged, _ = lass(model, images, **lass_kwargs)if converged: csr +=1return csr / n_examples
The paper sets the radius we search for adversarial examples to \(r = 30/255\) because it was small enough to not be noticed by a human evaluator. Here is an example.
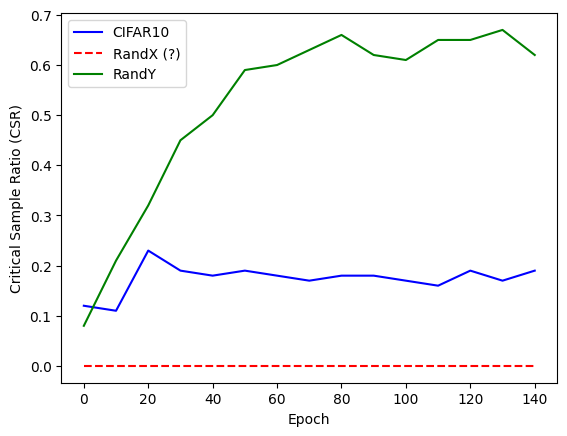
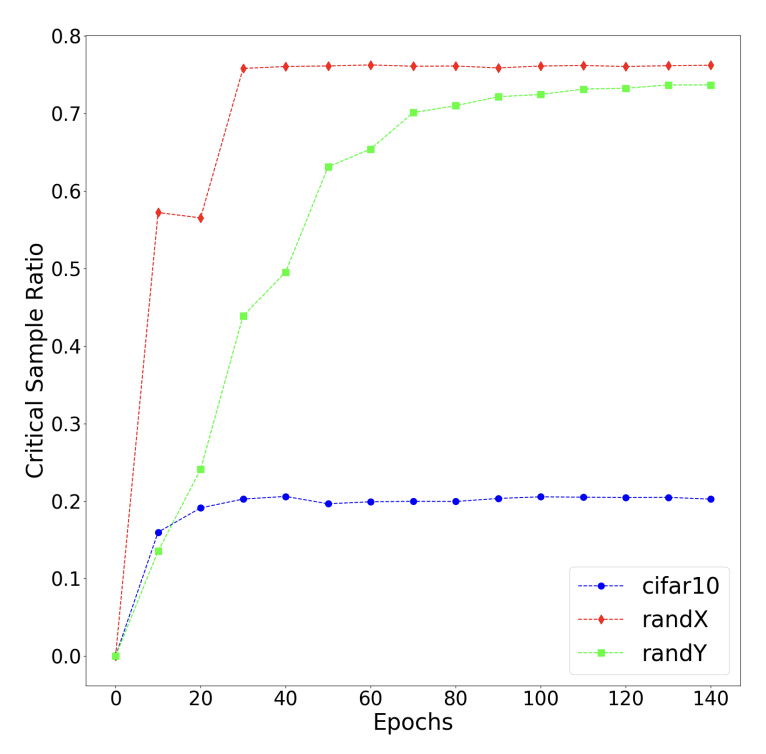
Where we observe roughly the same trend as in the paper displayed above while the network trained on real data has a somewhat constant CSR, the one trained on random labels has a higher CSR as training progresses. However, I could reproduce RandX’s behavior and obtained a constant CSR of 0. I tried different seeds, \(r\), and datasets (training and validation) without luck. My suspicion is that the model’s capacity and thus performance were not high enough (around 10% validation accuracy). I decided to stick with the paper’s architecture and move on.