The paper investigates the cause of batch norm’s benefits experimentally. The authors show that its main benefit is allowing for larger learning rates during training. In particular:
“We show that the activations and gradients in deep neural networks without BN tend to be heavy-tailed. In particular, during an early on-set of divergence, a small subset of activations (typically in deep layer) “explode”. The typical practice to avoid such divergence is to set the learning rate to be sufficiently small such that no steep gradient direction can lead to divergence. However, small learning rates yield little progress along flat directions of the optimization landscape and may be more prone to convergence to sharp local minima with possibly worse generalization performance.”
We attempt to reproduce figures 1-3, 5, and 6.
Convolutional BN Layer
As a reminder, the input \(I\) and output \(O\) tensors to a batch norm layer are 4 dimensional. The dimensions \((b, c, x, y)\) correspond to the batch example, channel, and spatial \(x\), \(y\) dimensions respectively. Batch norm (BN) applies a channel-wise normalization:
To make sure the layer does not lose expressive power we introduce learned parameters \(\gamma_c\) and \(\beta_c\). \(\epsilon\) is a small constant added for numerical stability. In pytorch, we can simply use the BatchNorm2d layer.
Experimental setup
Let’s set up our data loaders, model, and training loop as described in Appendix B of the paper.
Imports and model evaluation function
import torchimport torch.nn as nnimport torch.optim as optimfrom torchvision import datasets, transforms, modelsfrom torch.utils.data import DataLoader, Datasetfrom PIL import Imageimport numpy as npimport pandas as pdimport seaborn as snsimport matplotlib.pyplot as pltimport os, itertools, timeos.makedirs('logs', exist_ok =True)os.makedirs('models', exist_ok =True)seed =42np.random.seed(seed)torch.manual_seed(seed)device = torch.device('cuda'if torch.cuda.is_available() else ('mps'if torch.backends.mps.is_available() else'cpu'))def eval_model(model, test, criterion = nn.CrossEntropyLoss()): model.eval() correct, loss =0, 0.0with torch.no_grad():for images, labels in test: images, labels = images.to(device), labels.to(device) _, pred = torch.max(model(images), 1) correct += (pred == labels).float().sum().item() loss += criterion(model(images), labels).item()return loss /len(test.dataset), correct /len(test.dataset)device
The paper trains ResNet-110s on CIFAR-10, with channel-wise normalization, random horizontal flipping, and 32-by-32 cropping with 4-pixel zero padding. We’ll train the ResNet-101 included in torchvision but keep everything the same.
We first get the datasets and compute the channel-wise means and variances. Note: both the training and validation set have the same values.
We now define the transforms with data augmentation and data loaders with batch size \(128\).
Data transforms and data loaders
train_transform = transforms.Compose([ transforms.RandomCrop(32, padding =4), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize(means, stds),])# We do not perform data augmentation on the validation setval_transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize(means, stds),])train_set.transform = train_transformval_set.transform = val_transformtrain_loader = DataLoader(train_set, batch_size =128, shuffle =True)val_loader = DataLoader(val_set, batch_size =128, shuffle =False)
We’ll use torchvision’s implementation of ResNet-101, Xavier initialization, SGD with momentum \(0.9\) and weight decay \(5\times 10^{-4}\), and cross-entropy loss. We try to implement the training details and learning rate scheduling as mentioned in the paper:
“Initially, all models are trained for 165 epochs and as in [17] we divide the learning rate by 10 after epoch 50% and 75%, at which point learning has typically plateued. If learning doesn’t plateu for some number of epochs, we roughly double the number of epochs until it does”.
Init, and train functions
def xavier_init(m):ifisinstance(m, nn.Conv2d) orisinstance(m, nn.Linear): nn.init.xavier_uniform_(m.weight)def train_epoch(model, train, optimizer, criterion):# Trains the model for one epoch model.train() train_loss, correct =0.0, 0for images, labels in train: images, labels = images.to(device), labels.to(device) optimizer.zero_grad() output = model(images) loss = criterion(output, labels) loss.backward() optimizer.step() train_loss += loss.item() _, pred = torch.max(output, 1) correct += (pred == labels).float().sum().item()return train_loss /len(train.dataset), correct /len(train.dataset)def train(model, train, val, init_lr, plateau_patience =20): optimizer = optim.SGD(model.parameters(), lr = init_lr, momentum =0.9, weight_decay =5e-4) scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones = [82, 123], gamma =0.1) criterion = nn.CrossEntropyLoss() model.to(device) init_epochs =165 epoch =0 plateau_count =0 best_loss =None train_losses, train_accs, val_losses, val_accs = [], [], [], []while epoch < init_epochs and plateau_count < plateau_patience:# Train the model for an epoch loss, acc = train_epoch(model, train, optimizer, criterion) train_losses.append(loss) train_accs.append(acc)# Evaluate the model on the validation set val_loss, val_acc = eval_model(model, val, criterion) val_losses.append(val_loss) val_accs.append(val_acc)# Update the learning rate scheduler.step(val_loss)# Check for a plateauif best_loss isNoneor val_loss < best_loss: best_loss = val_loss plateau_count =0else: plateau_count +=1 epoch +=1# "If learning doesn’t plateu for some number of epochs,# we roughly double the number of epochs until it does."if epoch == init_epochs and plateau_count < plateau_patience: init_epochs *=2print(f'Epoch {epoch}/{init_epochs} | Learning Rate: {optimizer.param_groups[0]["lr"]} | 'f'Training loss: {train_losses[-1]:.4f} | 'f'Validation loss: {val_losses[-1]:.4f} | 'f'Validation accuracy: {val_accs[-1]:.4f}')return train_losses, train_accs, val_losses, val_accs
And we define a function to disable batch norm layers in a model by replacing them with identity layers:
def disable_bn(model):for name, module in model.named_children():ifisinstance(module, nn.BatchNorm2d):setattr(model, name, nn.Identity())else: disable_bn(module) # Recursively replace in child modules
Fig 1
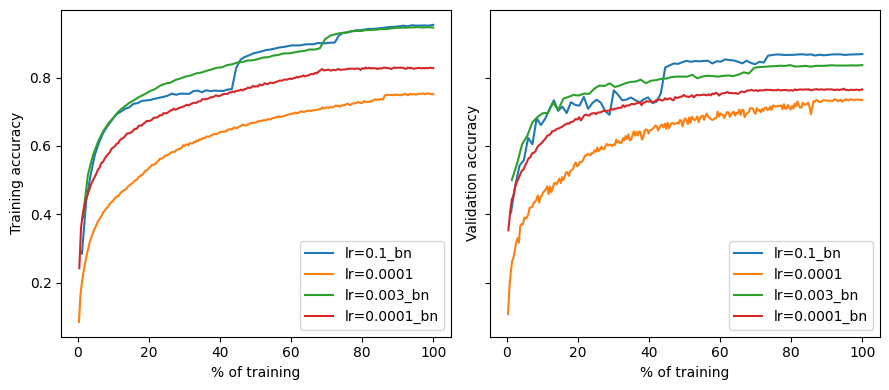
Figure 1 aims to demonstrate that batch norm’s primary benefit is that it allows training with larger learning rates.
The authors find the highest (initial) learning rate with which they can train an unnormalized model (\(\alpha = 0.0001\)) and compare its performance with normalized models trained with \(\alpha \in \{0.0001, 0.003, 0.1\}\). We train each model once (instead of five times to save on compute) and present train and test accuracy curves.
Train models
MODELS_DIR ='models'LOGS_DIR ='logs'for lr, bn in [(0.0001, False), (0.0001, True), (0.003, True), (0.1, True)]: s =f'lr={lr}'+ ('_bn'if bn else'')print(s) model = models.resnet101(num_classes =10) model.apply(xavier_init)ifnot bn: disable_bn(model) torch.save(model, f'{MODELS_DIR}/{s}_init.pth') data = train(model, train_loader, val_loader, init_lr = lr) torch.save(model, f'{MODELS_DIR}/{s}_end.pth') torch.save(data, f'{LOGS_DIR}/{s}.pth')
lr=0.1_bn took 83 epochs
lr=0.0001 took 263 epochs
lr=0.003_bn took 69 epochs
lr=0.0001_bn took 211 epochs
And observe the same general trends found in the original paper: similar learning rates result in about the same performance (red and orange) while increasing the rate yields better performance for normalized networks (blue) and training diverges for non-normalized ones (not shown).
Fig 2
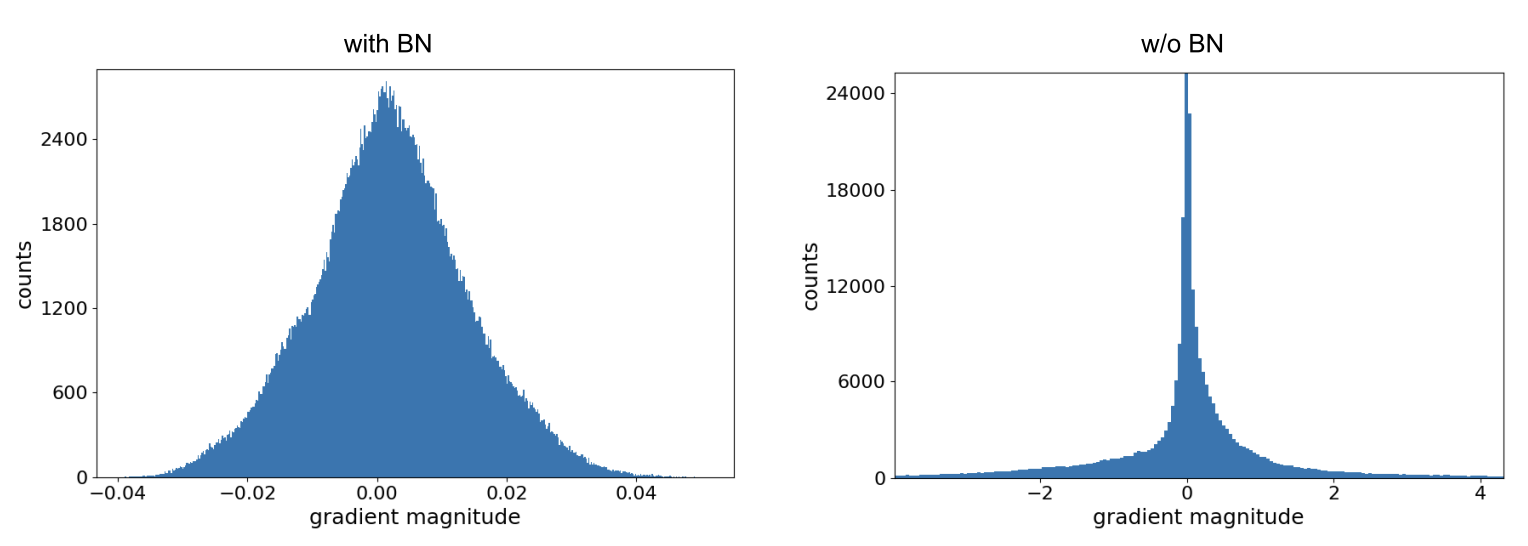
In Figure 2 the authors begin to investigate “why BN facilitates training with higher learning rates in the first place”. The authors claim that batch norm (BN) prevents divergence during training, which usually occurs because of large gradients in the first mini-batches.
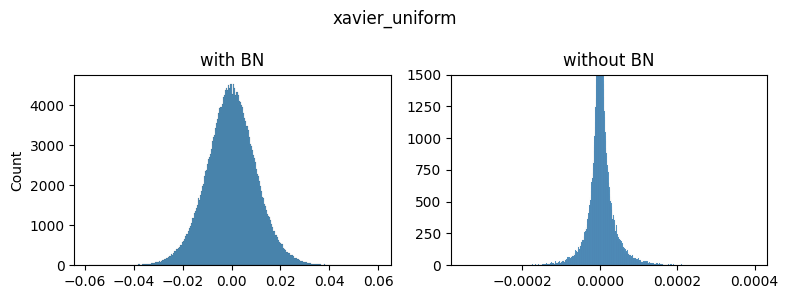
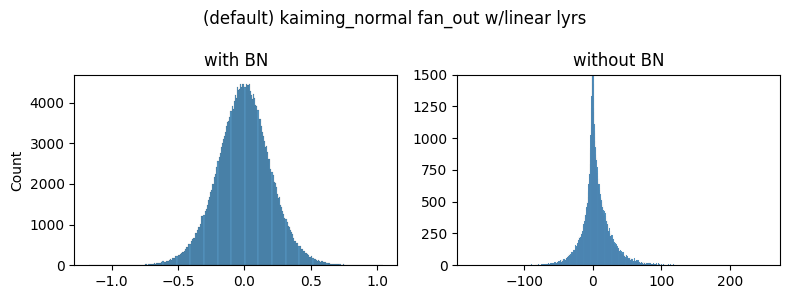
So, the authors analyze the gradients at initialization of a midpoint layer (55) with and without batch norm. They find that gradients in unnormalized networks are consistently larger and distributed with heavier tails.
I had trouble replicating this figure. I could not obtain the general shape and scale of the histograms they did:
At first, I thought because I was
looking at the wrong layer, +- 1 (then found it made little difference)
logging the gradient magnitudes incorrectly - why does the plot have negative values? (then found the authors plot the raw gradient)
misunderstanding the whole process
As I understood it, we initialize the model (using Xavier’s initialization), do a forward and backward pass on a single batch, and log the gradients at roughly the middle layer:
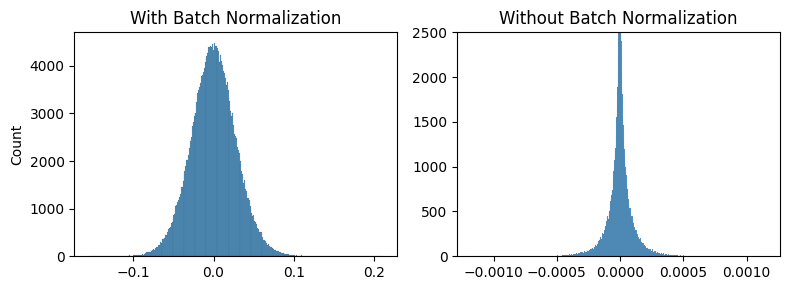
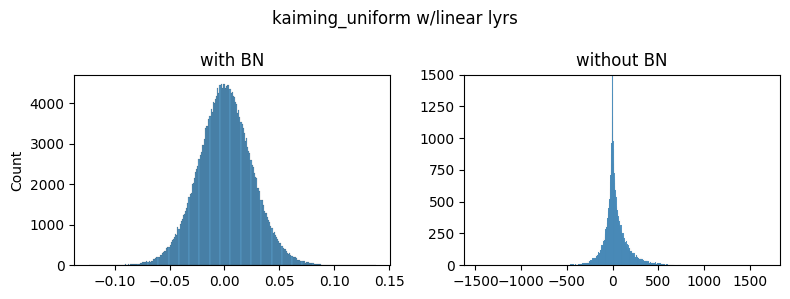
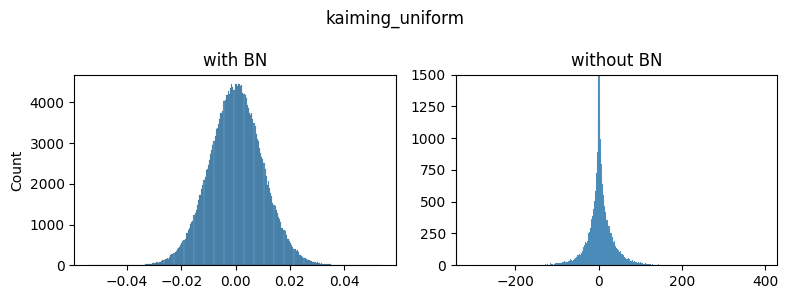
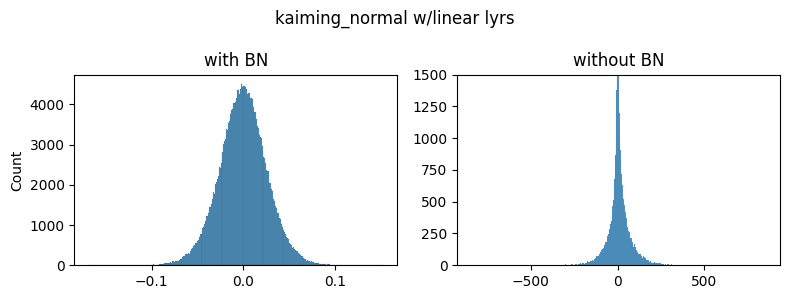
Although the unnormalized gradients are heavy-tailed, they are still much smaller than the normalized ones. I was stuck on this issue for a few days until I experimented with different initializations:
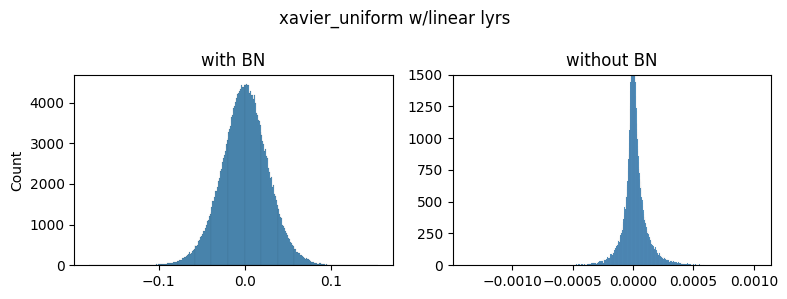
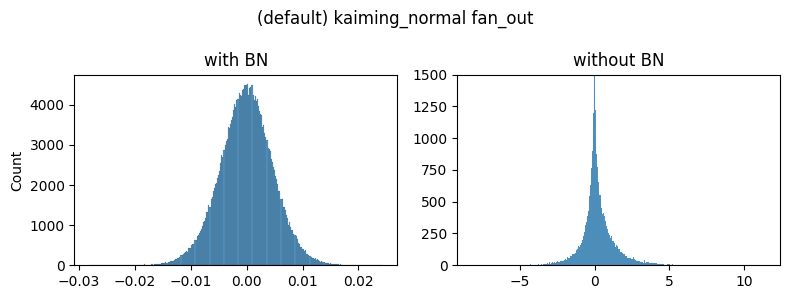
As you can see the general shapes, normal vs heavy-tailed don’t depend that much on the initialization scheme but the scales do. We could only achieve the same scale of the gradients presented in the paper by using the kaiming_normal scheme with fan=out (to preserve the magnitudes of the variance of the weights in the backward pass instead of the forward one) and applying it only to Conv2 layers. This is the default used by torchvision’s resnets.
Note: xavier_normal produced very similar shapes/scales as xavier_uniform so we don’t show it.
For the rest of the figures we’ll use the default init scheme:
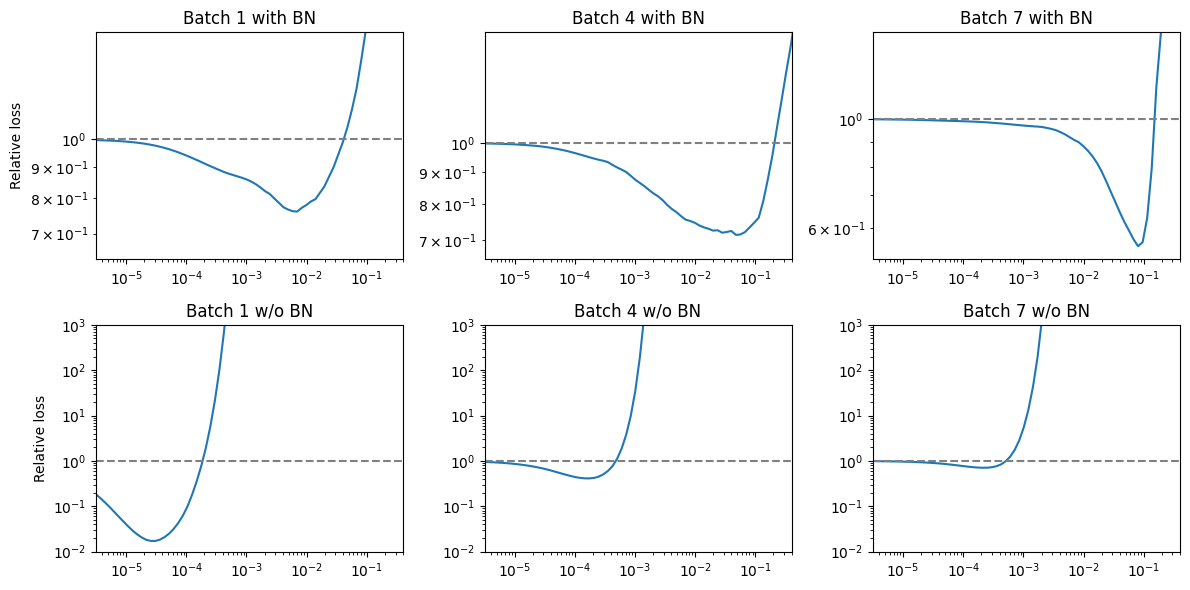
The authors then investigate the loss landscape along the gradient direction for the first few mini-batches for models with BN (trained with \(\alpha = 0.1\)) and without BN (\(\alpha = 0.0001\)). For each network and mini-batch they compute the gradient and plot the relative change in the loss (new_loss/old_loss).
We save the model’s and optimizer’s states (state_dict) before taking the tentative steps to explore the landscape and restore them before taking the actual step between batches.
Explore loss landscape
def fig3(model, init_lr, log_lrs, log_batches = [1, 4, 7]):# batch -> list of relative losses for each lr out = {} criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr = init_lr, momentum =0.9, weight_decay =5e-4)for i, (images, labels) inenumerate(train_loader): images, labels = images.to(device), labels.to(device)if i in log_batches: torch.save(model.state_dict(), f'models/model_state.tmp') torch.save(optimizer.state_dict(), f'models/optimizer_state.tmp') rel_losses = []for lr in log_lrs:for param_group in optimizer.param_groups: param_group['lr'] = lr optimizer.zero_grad() output = model(images) current_loss = criterion(output, labels) current_loss.backward() optimizer.step()with torch.no_grad(): output = model(images) tmp_loss = criterion(output, labels) rel_loss = (tmp_loss / current_loss).item()# print learning rate, current loss, tmp loss, relative loss (at 4 decimal places)print(f'{lr:.5f}{current_loss:.5f}{tmp_loss:.5f}{rel_loss:.5f}') rel_losses.append(rel_loss) model.load_state_dict(torch.load('models/model_state.tmp')) optimizer.load_state_dict(torch.load('models/optimizer_state.tmp')) # If loss is nan of int, break. Unlikely to recover.if torch.isnan(tmp_loss).item() or torch.isinf(tmp_loss).item(): rel_losses.pop()print('breaking')break out[i] = rel_lossesif i ==max(log_batches): break# take the actual step optimizer.zero_grad() output = model(images) loss = criterion(output, labels) loss.backward() optimizer.step()return outlrs = np.logspace(-5.5, 0.5, 80)# With BNmodel = models.resnet101(num_classes =10)model.to(device)model.apply(init_net)with_bn = fig3(model, init_lr =0.1, log_lrs = lrs)# Without BNmodel = models.resnet101(num_classes =10)model.to(device)disable_bn(model)model.apply(init_net)without_bn = fig3(model, init_lr =0.0001, log_lrs = lrs)
Although we get roughly different scales, we observe that unnormalized networks reduce the loss only with small steps while normalized ones can improve with a much larger range, as in the paper.
Fig 5
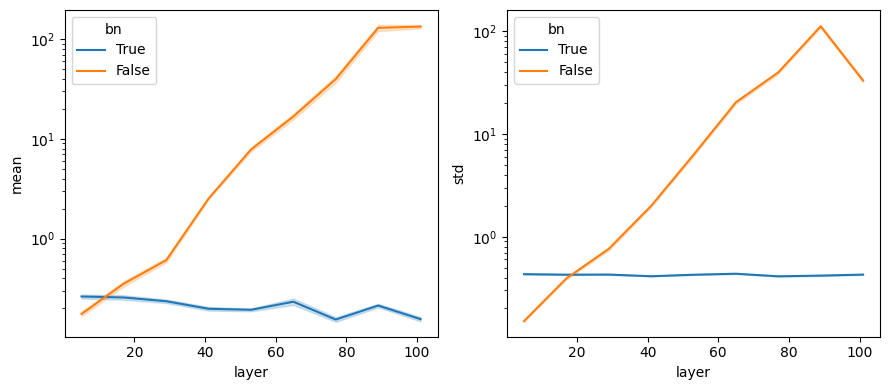
Figures 5 and 6 explore the behavior of networks at initialization. Figure 5 displays the mean and variances of channels in the network as a function of depth at initialization. We initialize \(10\) networks and use forward hooks to log their channel mean and standard deviations.
Log activation stats
df = []def log_activation_stats(layer_name, key):def hook(module, input, output):with torch.no_grad(): df.append({'bn': key,'layer': layer_name,'mean': output[:, 0, :, :].mean().abs().item(),'std': output[:, 0, :, :].std().abs().item() })return hookfor _ inrange(10):for bn in [True, False]: model = models.resnet101(num_classes =10) model.to(device)ifnot bn: disable_bn(model) model.apply(init_net)# Layers to log activations from log_layers = [] # (n, name, layer) n =1for name, layer in model.named_modules():if'conv'in name: n +=1if n inlist(range(5, 101+12, 12)): log_layers.append((n, name, layer))for n, _, layer in log_layers: layer.register_forward_hook(log_activation_stats(n, str(bn)))for images, _ in val_loader: model(images.to(device))df = pd.DataFrame(df)
Code
f, (ax1, ax2) = plt.subplots(1, 2, figsize = (9, 4))sns.lineplot(data = df, x ='layer', y ='mean', hue ='bn', ax = ax1)ax1.set_yscale('log')sns.lineplot(data = df, x ='layer', y ='std', hue ='bn', ax = ax2)ax2.set_yscale('log')f.tight_layout()
We observe, consistent with the findings in the paper, that activation means and standard deviations increase almost exponentially in non-normalized networks, whereas they remain nearly constant in normalized networks.
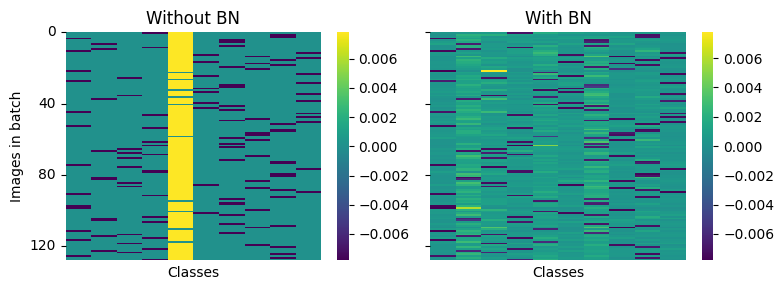
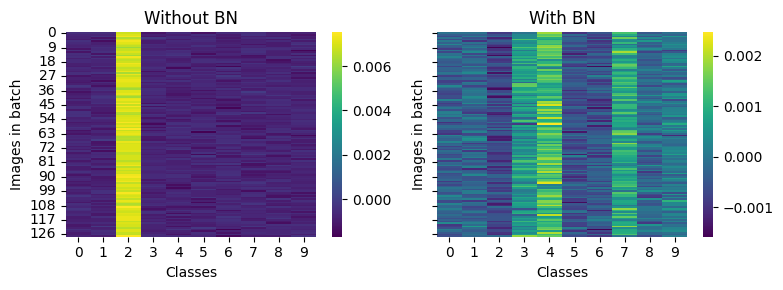
Fig 6
The large activations in the final layers for unnormalized networks in the previous figure make us suspect that networks are biased towards a class. The authors investigate whether this is the case by looking at the gradients in the final (output) layer across images in a mini-batch and classes.
Note: Don’t confuse this with the last fully connected layer of the network. We are looking at the gradients of the output logits themselves. We need to use retain_grad on the output (non-leaf node) to calculate its gradient on the backward pass.
And basically observe the same results as the paper:
“A yellow entry indicates that the gradient is positive, and the step along the negative gradient would decrease the prediction strength of this class for this particular image. A dark blue entry indicates a negative gradient, indicating that this particular class prediction should be strengthened. Each row contains one dark blue entry, which corresponds to the true class of this particular image (as initially all predictions are arbitrary). A striking observation is the distinctly yellow column in the left heatmap (network without BN). This indicates that after initialization the network tends to almost always predict the same (typically wrong) class, which is then corrected with a strong gradient update. In contrast, the network with BN does not exhibit the same behavior, instead positive gradients are distributed throughout all classes.”
Running the above code multiple times, however, sometimes results in two or three yellow columns. We think this is because different mini-batches behave slightly differently or due to initialization randomness. Below, we log and average the gradients for a whole epoch and find much more consistent behavior.
I gained a better understanding and intuition of why Batch Normalization (BN) works. More importantly, I got comfortable with PyTorch and debugging training, etc.
Pytorch specific:
Basics of image augmentation: basically use transforms and compose them.
Learning rate schedulers: they exist, are really useful, and pytorch has a good assortment of them.
state_dict preserves optimizer’s param groups and args (learning rates, etc.) but also momentum buffers.
hooks as useful debugging and visualization tools.
retain_grad is required to get gradients of non-leaf nodes like the output logits.
For the large training runs, I also experimented with jarvislabs.ai as a provider. In-browser notebooks and VS Code, and direct SSH/FTP access were pretty nice. I could not work out funkiness with VS Code remote windows. Used